|
|
Библиотека Интернет Индустрии I2R.ru |
||
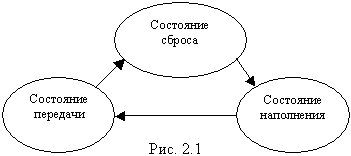
Управление памятью. Часть 3: Буферная памятьВсе вопросы и правила по ведению этой статьи были описаны в части 1. Автор ещё раз замечает, что он активно использует свои определения, и теоретические выкладки, которые никак не претендуют на официальный статус научных, но от этого хуже не становятся. Буферы Ещё один вид памяти, часто используемый, но нереализованный в виде API. Он берёт своё начало от вопросов по схемам редактирования файлов, что видимо, является темой последующих статей. Буферная память как следует из названия - это по сути дела то же, что и буферы. Но, в конце концов, такое понятие было обобщено и систематизировано, так как предлагаемая схема использования нашла себя и в других областях, отличных от вопросов буферизации. В общем случае темы буферизации и дефрагментирования являются довольно большими, очень скучно и нудно излагать их в одной статье, поэтому здесь будут лишь объяснения, связанные с буферной памятью, а все вопросы и причины, почему именно, так или иначе, таятся глубже. Буферная память имеет несколько назначений. Первое назначение: Целью механизма буферной памяти, (или то же что <прокси- систем>) является уменьшение потребляемых ресурсов объектом приёмником, требующего сравнительно больших затрат, путём уменьшения частоты поступления потока данных в объект- приёмник. Второе назначение: Целью механизма буферной памяти является создание участка оперативной памяти для отработки процессов рейдеринга памяти, и других процессов, время выполнения которых зависит от размеров памяти. Читатель может заметить ещё одну цель создания буферов. Это проведение некоторого рода операций над файлами большого размера, которые не умещаются в оперативной памяти. Однако следует считать, что этот случай попадает под первое назначение буфера, так как нехватку оперативной памяти можно понимать как большие затраты ресурсов. Таким образом под затратой ресурсов следует понимать как источник хранения данных, так и время выполнения кода. Буферной памятью называется - объект памяти, которым владеют одновременно два объекта, не связанные между собой. В этом определении важно два слова: <ДВА ОБЪЕКТА> и <НЕ СВЯЗАННЫЕ>. В случае нарушения одного из этих условий мы автоматически попадаем в неизведанный мир Оморфо программирования. Обычно два объекта, владеющие буферной памятью, называются по типу их отношений с буфером: <источник> / <приёмник>. Один объект <источник> помещает данные в буфер, а другой объект - <приёмник> снимает их с буфера. Но (!!!) сами эти объекты не связаны между собой ни какой архитектурной зависимостью кода! Между прочим, такая модель взаимодействия получила название прокси, когда существует система-посредник между двумя системами. То есть буфер иными словами является прокси-объектом, а источник - буфер - приёмник - прокси-системой. Рабочий цикл буфера. Буферная память имеет три основных состояния:
Состоянием наполнения называется момент времени, в котором информация помещается в буфер. Состоянием передачи называется процесс, когда информация из буфера перемещается в объект приёмник. Графическое изображение цикла работы буфера представлено на следующем рисунке 2.1 .
Состояние сброса является начальным состоянием буферной памяти, после того как она заказана и выделена. Буферную память, как правило, заказывает третье лицо, и назначает её владельцам: источнику и приёмнику. То есть источник, и приёмник не подозревают, что они работают через буфер. Очень часто буферную память заказывает и объект приёмник, который, по сути, управляет выходным хранилищем данных. В этом случае, он подключается к объекту источнику и передаёт ему буфер. Но никогда (!!!) буферную память не заказывает объект источник, на это есть много веских причин, которые выходят за рамки повествования. Можно считать, что объект источник должен быть сконструирован так, чтобы он не подозревал, что работает с буфером. Конечно, на любое правило есть исключения, но в большинстве случаев, такое утверждение указывает на неоптимальность управляющего алгоритма, либо на возможность потенциальной ошибки в нём. Объект источник помещает поток данных в буфер, при этом этот процесс передачи может быть организован двумя методами:
В первом случае считается, что источник заполняет буфер посегментно, фиксированными блоками памяти. Во втором случае, заполнение буфера происходит произвольным образом. По способу заполнения можно выделить следующие виды взаимодействия:
В первом случае источник заполняет буфер во время специальных периодов называемых сессиями, во втором случае буфер заполняет в каком-либо непрерывном цикле, и в третьем случае буфер заполняется в произвольный момент времени. И, наконец, по способу доступа источника и приёмника:
Если память в буфере занимается сегментно, то тогда возникает возможность предсказывать переполнение, и передать данные в приёмник в любой момент, когда он будет готов для приёма. В подобных алгоритмах активно используются асинхронные вызовы и событийные системы потенциалов, но можно ограничиться и традиционными способами. Если заполнение выполняется сессиями, то возникает возможность освобождать буфер каждый раз после сессии, если приёмник готов к передачи, но этим не стоит злоупотреблять, так как система буферной памяти разрабатывалась именно чтобы сделать обращение к выделению основных блоков памяти менее частым. В этом случае можно использовать систему потенциальных предсказаний. В случае циклического заполнения процесс передачи осуществляется в зависимости после последнего гарантированного удачного помещения данных в буфер. Удачным гарантированным помещением в случае сегментной схемы считается - последний помещающийся в буфер сегмент. Так же хочется отметить по-секторную модель, в которой имеется возможность одновременных процессов считывания и записи в буфер, это актуально при многониточном программировании, а так же в нелинейных системах. В этом случае буфер делиться на несколько секторов. Когда заполняется один сектор буфера, следующий переходит в состояние заполнения, а заполненный сектор переходит в состояние передачи. Выделение памяти буферу. Вопрос создания буфера открывается в момент создания объекта приёмника. И как нестранно такое утверждение - правило. Сколько же памяти следует отдавать на буфер? Вот довольно жёсткий принцип: Размер буфера должен быть таким, чтобы суммарное время выполнения кода обслуживающее режим наполнения, было бы равно времени выполнения кода, выполняющего режим передачи. При этом код исполняемый объектом источником должен иметь приемлемое время исполнения. В первой части определения разговор идёт касательно так называемого первого назначения буфера. Обычно код организующий выделение памяти средствами ОС является <тяжёлым кодом>, то есть он требует сравнительно много времени на выполнение. Предположим, если вы выполняете какие-то циклические действия над потоком ввода из файла, то было бы чрезвычайно расточительно обращаться к диску за каждым байтом. В этом случае, с диска считывается сразу дамп памяти, а некая операция выполняется над этим дампом. Данный пример, аналогичен, так же если вместо источника диска, подставить источник - некую функцию, конвертирующую данные, либо что-то ещё. Во второй части правила говориться о затратах на использование ресурсов источником, подобно примеру выше - это диск. Диск - медленное устройство и требует сравнительно большего времени для получения/передачи данных. Вместо диска можно подразумевать совокупность процедур, работающих с памятью, и время выполнения которых зависит от размера обрабатываемой памяти. Примером таких процедур могут служить процедуры рейдеринга памяти, выполняющих её дефрагментацию. Однако, несмотря на всё вышесказанное, прямое использование этого правила не возможно, так как число влияющих факторов на выбор размера буфера намного больше из тех, что рассмотрены в правиле. На выбор размера буфера так же влияют: гранулярность памяти, физический размер страниц, методы выделения памяти, удобство работы обслуживающих алгоритмов, и др. Так же фактором выбора размера буфера является место его размещения и метод получения. Буферную память можно разместить как статически, то есть заранее расположенную в секции неинициализированных данных, так и динамически выделенную. В том случае, если буфер создаётся для кэширования вывода в файл, можно разместить буфер прямо на первых страницах файла, однако это чревато последствиями перекачки всех данных при сохранении файла. Можно размещать буфер и в хвосте файла, с каким-то запасом, и постепенно передвигать сам буфер по мере заполнения файла. Вот как это выглядит на практике:
Здесь серым цветом выделена заполняющаяся часть файла, а зелёным - буфер. Остальное - незанятое пространство. Если заполнение дойдёт до границ буфера и потребует большего пространства, тогда информация в буфере будет переработана, а сам буфер будет перемещён дальше, вот так:
По сути, данный метод является как бы обычной последовательной записью в файл, но с промежутками. И, тем не менее, это считается полноценным случаем буфера. Буферную память целесообразно размещать в области виртуальной памяти, т.е. в файле подкачки. В любом случае размер буфера обязан быть кратен размеру страницы в данной системе. Однако гранулярность выделения памяти в Win32 является 64-bits, что создаёт жёсткие ограничения на размер буфера. Поэтому стоит выделять некоторое пространство памяти для нескольких буферов, и давать им размеры и базовые адреса по размерам страниц. (Более подробно о стратегиях выделения памяти в следующей части.) Один буфер для многих и многоуровневая буферизация. Широкий круг задач приходится выполнять жёстко последовательно. Например, ввод с клавиатуры может быть направлен в данный момент времени только в один источник. Этим можно воспользоваться для организации одного буфера для использования многими. Можно применить технологию ускользающих. В этом случае сброс буфера будет выполняться либо когда он наполнен, либо когда к буферу обращается другой объект-хозяин. Место под такой буфер можно зарезервировать в неинициализированном разделе, если он не превышает 8kb - 12kb оперативно памяти. Использование статических буферов является более эффективными по способу адресации, и тем эта эффективность выше, чем больше кода использует данный буфер. При этом при использовании статически размещённого буфера отпадает головная боль за слежением очистки мусора и выделения памяти, что сильно влияет на качество системы. Статические буфера желательно использовать, где только это возможно, хотя это возможно далеко не везде. К счастью существует метод многоуровневой буферизации. Как следует из названия, этот метод представляет собой наличие объекта хозяина у буфера, где объект хозяин сам является буфером. Буфер, который <стоит> ближе к действительному источнику именуется первым, а все последующие по порядку. Обычно каждый последующий буфер имеет меньшую частоту сброса, а значит, занимает больше памяти. Метод многоуровневой буферизации позволяет комбинировать достоинства нескольких приёмов размещения буферов. Например, первым буфером может являться буфер размещённый статически, а вторым - размещённый динамически. Примером использования многоуровневой системы буферизации может послужить API работы с файлами. Вы можете использовать кокой-то свой буфер для выполнения задач, когда система прозрачно для вас выполняет ещё одну буферизацию. А если вспомнить про физический буфер, находящийся в самом жёстком диске, то мы получим трёх уровневую систему буферизации ввода. Определённый интерес представляет использование <какой-либо памяти> и буфера. Модель работы такой системы выглядит так:
В качестве промежуточной памяти может выступать какой либо её блок, размещённый статически и работать по методике ускользающих. Такая система нашла широкое применение на практике, и мы рассмотрим её подробней несколько позже. Важно отметить следующее, что в данной многоуровневой системе, первый объект-буфер не является либо совсем буфером, либо является буфером неполноценным, так как не отвечает одному из назначений буфера, или не имеет буферного цикла. API буферов. Обычно всё-таки следует организовать некоторый локальный API по работе с буферной памятью. Первая важная функция, которая должна существовать это, конечно же, CreateBuffer. Вот возможный её прототип:
Функция CreateBuffer обязана сделать все предварительные настройки, и что важно найти и выделить нужный блок памяти заданного объёма. Теперь после удачного выделения буфера, объект источник перед помещением данных в буфер вызывает функцию OpenBuffer(), а по окончании заполнения CloseBuffer(). Вот почти и всё API: POINTER OpenBuffer ( // то же для функции CloseBuffer hbuffer, // хэндл буфера size // требуемый размер ); Функцию DestroyBuffer(), приводить не будем. Но призрачная лёгкость API вовсе не адекватна реализации. Поэтому рассмотрим подробнее, что должно происходить в той или иной функции буферного API. CreateBuffer() Функция CreateBuffer имеет пять параметров, первые три из которых являются обязательными. FType представляет собой набор флагов определяющих содержание буфера и особенности его строения. В первой главе была рассмотрена классификация буферов. В частности интерес представляет секторная организация буфера, и особенность его заполнения. Вот возможный формат параметра ftype: (порядок бит как в цельном DWORD, то есть направление возрастания адресов соответствует более меньшему порядку бит.)
Если ftype равно нулю, значит, заказан самый обыкновенный буфер и параметр sec_size обязан быть нулевым. В этом случае действия функции тривиальны, она должна разместить полученные данные в структуре BUFF$$_OBJ, которая описана далее:
Кроме задачи выделения памяти под буфер, в задачу создания входит верное заполнение полей структуры, а так же несколько тонкостей. Если буфер имеет посекторную организацию, то функция должна разместить так же структуры для описания секторов. Указатель на эти дополнительные структуры размещается в элементе pbase, который при отсутствии секторов должен указывать на его базовый адрес буфера. Обратите внимание, что при секторной организации элементы структуры BUFF$$_OBJ характеризуют не весь буфер, а только текущий его, рабочий сектор. Вся информация о секторах хранится в структуре BUFF$$_SECTOR:
После данной структуры следует массив счётчиков свободного места в секторах, где порядок элемента в массиве соответствует порядку следования в памяти секторов. Одновременно данный элемент служит так же и флагом занятости сектора, когда следует найти свободный сектор, нулевое значение соответствует незанятому сектору. OpenBuffer() Функции Open/Close предназначены для предоставления свободной записи данных в память буфера, а так же для прямого использования этой памяти. После того как вызвана функция OpenBuffer, некая область буфера становится доступной для работы. Хочется заметить, что в случае ошибки программы в нарушении границ фрагмента, результаты непредсказуемы. Это можно считать неким недостатком Open/Close, так как такую ошибку трудно выловить. И тем немее использование функций Open/Close без сомнений высокоэффективно. Так как буфер используется и как буфер, и как простая выделенная память. Несколько особенностей работы этих функций определяет вид буфера. Никаких вопросов не возникает, если это простой буфер. В случае секторной организации буфера, функции следят не за всем буфером, а за текущим сектором. А если тип буфера содержит установленный флаг посегментной передачи, в функциях Open/Close теряет смысл параметр size. Отметим, что параметр size в функции CloseBuffer() указывает действительное количество используемой памяти. Оно может быть и меньше заказанного. WriteBuffer() Более классическим методом является наличие функции WriteBuffer(), которая обязана помещать данные непосредственно в буфер. Особенности этой функции от остальных является тот факт, что данные переданные ей уже определены. Это облегчает задачу, и предоставляет возможность оптимизации записи. Такая оптимизация становиться, возможна при посекторной организации буфера. В этом случае, если буфер не содержит достаточного места в текущем секторе, функция может поискать свободное место в других секторах, и заниматься дефрагментацией данных. В случае сегментной передачи функция WriteBuffer требует только хэндл буфера, и часто используется при циклическом заполнении. Buffer_IncSize() Эта функция используется совместно с OpenBuffer(), для увеличения предварительно заказанного пространства. Вот её прототип:
Когда буфер наполнен: Теперь важный момент, когда происходит событие: <буфер наполнен>. Такое событие может произойти при вызове любой из функций OpenBuffer/Buffer_IncSize/WriteBuffer. Но процедура передачи может иметь длительное время выполнения, а так же существуют моменты, когда передача данных происходит на напряжённых участках работы программы. Если всё выше перечисленное не волнует, то событие переполнения возникает при вызове любой из трёх функций, если на момент вызова функции память не может быть выделена. Исключение составляют сегментные передачи. В данном случае переполнение буфера возможно предсказать. Для определения особенностей перехода в режим передачи, существует флаг отложенного сброса. Этот флаг влияет на поведение вышеприведенных функций. При возникновении события переполнение функции не вызывают немедленное выполнение процедуры обслуживающей передачу информации с буфера, а вместо этого эти функции могут спонтанно выделить из общей кучи память (так называемая внеплановая память буфера). А при вызове функции CloseBuffer() освободить внеплановую память, и выполнить процедуру передачи. Причина, по которой используется именно такой алгоритм, не так очевидна. Дело в том, что в 95% случаев функция CloseX вызывается в момент, когда скорость выполнения уже не столь критична, и когда общее напряжение ресурсов меньше чем после OpenX. В этом моменте есть много подобных сценариев, и вариаций. Например, можно проверит, выполнив запрос у объекта приёмника можно ли в данный момент быстро выполнить передачу данных без больших затрат времени. Если да, функция вызывает режим передачи, если нет - алгоритм выше. Особенно интересным случаем является тот, когда объект-приёмник возвращает ошибку, указывающую на невозможность передачи. В этом случае, менеджер буферной памяти, обязан отказать в запросе выделить память буфера и указать на серьёзность ошибки. Этот неприятный момент означает, что код использующий буфер обязан немедленно прекратить операции буферизации, и передать управление аварийным обработчикам. Если этого не сделать, то результаты становятся неуправляемыми. Что так же можно рассматривать как недостаток организации буферной памяти. Особенным случаем наполнения является секторная схема. Когда заказ памяти буфера не может быть оформлен в текущем секторе, функция доступа может подыскать свободный сектор, а предыдущий сектор оставить до вызова функции CloseBuffer(). Такая схема является в 95% случаев гарантированно высокоэффективной, как уже говорилось. Она используется также и для сегментной организации заполнения. В этом случае передача данных осуществляется в функции CloseBuffer(), когда был запрошен последний сегмент! Обратите на это внимание! А не тогда когда будет вызвана следующая функция OpenBuffer(), и вся память буфера будет занята. Управлять временем вызова процесса передачи можно так же при помощи дополнительного API: FastBufferWrite(), FastBufferOpen(), FastBufferClose(), и т.д. А так же введением дополнительной функции принудительного возбуждения процесса передачи: TransferBufferData(). И, наконец, то, как осуществляется обработка события переполнения. После предварительного кода функции, вызывается метод, указатель на который храниться в элементе pmethod структуры BUFF$$_OBJ, что приведена выше. Такая организация задумана, чтобы сделать, менеджер более гибким при расширении, и исключить длительные проверки флагов в ftype, то есть повысить скорость. Именно метод, который назначается данному буферу, настраивает всё необходимое, чтобы потом передать управление процедуре передачи объекта приёмника, указатель на которую хранится в pcb_receiver структуры BUFF$$_OBJ. Между прочим указателем pmethod можно воспользоваться, чтобы дать вмешаться в обработку события переполнения объекту приёмнику, а так же кому будет угодно. Прямой доступ к памяти буфера Когда скорость выполнения является важной, если не критичной, вызов нескольких функций ради какого-то там наблюдения за переполнением. Тем более в циклах, когда на счету каждый такт. В этом случае наблюдение за счётчиками буфера возможно было бы предоставить самому коду объекта источника. Но как это выполнить, оставив нужный режим инкапсуляции API? В этом случае следует предусмотреть дополнительные функции, которые будут возвращать копии элементов структуры BUFF$$_OBJ counter, и pointer, и код источника опираясь на эти элементы сам, будет следить за переполнением буфера. Для этого понадобятся следующие функции: FreeOpenBuffer(), FreeCloseBuffer(), OverflowBuffer(). А так же GetPramBuffer()/SetParamBuffer. Оставляю их функционирование на самостоятельную проработку. Заключение За кадром осталось многое. Мы даже не коснулись асинхронных процессов, и т.д. Но, тем не менее, базовое освоение работы буферов необходимо даже для простых задач. Вы, без всякого сомнения, можете попробовать осуществить этот нехитроумный API, и потом уверен, он окупиться ещё не раз. Кашинский Дмитрий Владимирович |
|
| 2000-2008 г. Все авторские права соблюдены. |