|
|
Библиотека Интернет Индустрии I2R.ru |
||
FineReader как детектор лжи
Фирма ABBYY в соответствии с пословицей о выборе сезонов подготовки телег и саней выпустила летом сразу три варианта шестой версии программы FineReader: Professional Edition/Corporate Edition/Scripting Edition. Кататься на них до сессии пока некуда, но запрячь в сканер и опробовать можно. Не пугайтесь, мы не будем рассматривать использование этих тяжеловозов по прямому назначению. А последуем осенней традиции учебного самообмана: разложим на столе умные учебники, откроем только что начатые конспекты и, прочитав пару абзацев теории, незаметно отвлечемся на мелочи. Итак, формально FineReader 1 (рис. 1) - омнифонтовая система оптического распознавания текстов (толкования цитируемых терминов «по версии разработчика» сведены в таблице). Термины и определения
Процесс чтения с точки зрения науки есть опознание и декодирование изображенных на бумаге символов. И он существенно отличается даже у разных людей 2. Чтобы выяснить локализацию мозговой активности при чтении, ставились непростые и небезопасные эксперименты на, очевидно, живых и грамотных добровольцах, и после ознакомления с их содержанием пытливые инопланетяне из фильмов ужасов покажутся неземными гуманистами. Я не решился проводить нечто подобное даже в отношении «чтеца» электронного, ограничившись простым наблюдением за его внешними реакциями в сравнении с реакциями человеческими (сходство которых разработчики декларируют, не поясняя деталей).
Помните ли вы, как научились читать и что тогда изменилось? У меня, например, ухудшился сон. Содержание прочитанного значения не имело - влиял сам факт развития способности «распознавания». Раньше в снах не было лихорадочной активности мозга, пытающегося «читать» - текст воспринимался как узор. Другое дело - сон, «снятый» по материалам дней школьных и последующих, отягощенных «тайной чтения» - тут, сдавая экзамен по всем дисциплинам зараз, я лихорадочно вглядываюсь в «знакомую» книгу и не могу назвать ни буквы, хотя иллюстрации запоминаю до утра. А всё из-за того, что некоторые зоны мозга спят «крепче» других. Кстати, следует отметить, что носители восточных языков часто способны к распознаванию приснившихся иероглифов. Дело в том, что в японском и китайском языках употребляются две формы письменности. Кандзи (рис. 2, слева) использует символы почти пиктографического характера, отображающие не звуки, а предметы и понятия. Кана (рис. 2, справа) - символы, означающие комбинации звуков или слоги. При этом зрительно-пространственное восприятие иероглифов осуществляется правым полушарием мозга, а символов Кана, как и любых европейских букв, - левым 3.
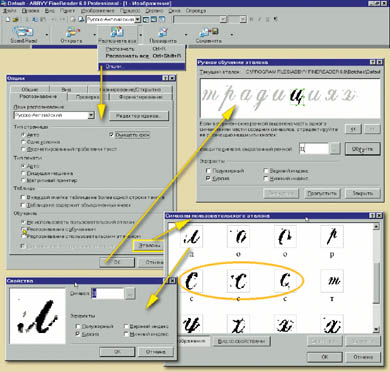
«Сны» в FineReader’е, конечно, невозможны 4, ведь FineReader всего лишь распознает символы, а мы еще и осознаем их смысл. А вот трудности узнавания без понимания смысла распознанного хорошо видны при попытке переписать, например, колонку ответов к кроссворду - все слова знакомы, но их неожиданная последовательность заставляет сверять каждый слог. Елена Григоренко, доцент факультета психологии МГУ и одновременно генетик, профессор Йельского университета (Коннектикут, США), приводит такое сравнение: «Если человек не умеет играть на виолончели, а его заставят, он будет неизбежно „застревать“ на технических деталях: как держать смычок, куда ставить палец и т. д.». Что и происходит в FineReader’е: анализируя графическое изображение, переданное сканером, «система сначала выдвигает гипотезу об объекте распознавания (символе, части символа или нескольких склеенных символах), а затем подтверждает или опровергает ее». Данный процесс доступен для визуального контроля в специальном режиме «обучения», для выхода в который необходимо перед распознаванием трудночитаемого шрифта установить опцию «Распознавание с обучением» (рис. 3). В соответствующем окне видно, как именно FineReader пытается «обнаружить все структурные элементы и связывающие их отношения». При этом пользователю предлагается самостоятельно указывать FineReaderу «правильное» значение распознаваемых символов, соглашаясь или корректируя его «гипотезы». Все поучения FineReader сохранит в так называемом пользовательском эталоне.
Для получения сколько-нибудь полезного пользовательского эталона соответствия отсканированных элементов изображения буквам, цифрам и знакам, необходимо пройти в ручном режиме как минимум одну отсканированную страницу (примерно две тысячи знаков). Сверяясь с русскоязычным файлом справки, попробовать это очень просто и поучительно. Дело в том, что FineReader помещает в пользовательский эталон все варианты начертания нераспознанного символа. Анализируя эталоны рукописей большинства людей, можно заметить значительное число вариантов написания некоторых букв на фоне двух-трех стабильных начертаний для остальной части алфавита. Психологи используют это свойство почерка для выявления травмирующих образов и ситуаций, сохранившихся у испытуемого с дошкольного периода. «Обученный» FineReader неплохо справляется с чертежными и архитектурными шрифтами в написании студентов старших курсов и некоторыми стабильными учительскими почерками. Но тут следует констатировать не столько приближение машины к человеку, сколько уподобление профессиональных писарей машинам. Для практических же целей не следует переоценивать возможности этой функции: может статься, что «…затраты на обучение будут больше, чем полученный выигрыш в качестве распознавания». При этом «необученный» FineReader, коверкающий некоторые слова и знаки, хорош в совершенно неожиданном качестве… детектора письменной лжи! С фрейдистских трудов принято считать, что подсознание просматривается через оговорки (в нашем случае опечатки). Современная многоступенчатая корректура, казалось бы, не оставляет для подсознания никаких лазеек, но… Не тут-то было - «мозг хитрее человека», и для обмана литредакции он призывает в помощь художника-оформителя. В результате наиболее дискуссионные пассажи набраны «нераспознаваемым» шрифтом на пестром фоне - типично детский прием, когда неуверенный в собственных знаниях первоклассник произносит ключевые слова ответа исключительно невнятно. Три примера работы FineReadera в режиме детектора лжи помогут вам научиться выявлять подобные «текстовые уловки» невооруженным глазом. При этом мы сравним «наш» и «их», отягощенный законодательным регулированием, подходы к «маскировке» рекламной неправды.
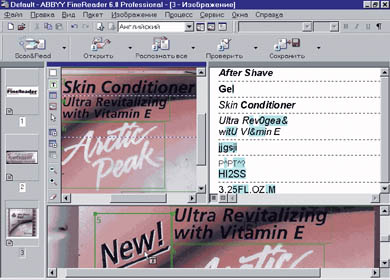
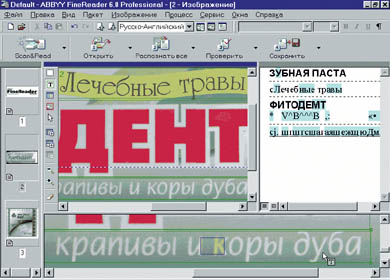
На рисунке 4 представлен результат чтения FineReader’ом этикетки средства после бритья известной международной компании. Слова «Arctic Peak» и «revitalizing» практически нераспознаны, что коррелирует с их смысловой нагрузкой: в Арктике нет «пиков» - это не Антарктида, а «revitalizing» - «оживление» - на данном препарате звучит сродни «реинкарнации» 5. На рисунке 5 - отечественная работа. В отличие от предыдущего примера всё наоборот: в диссонансе слоганов «лечебные травы» и «с экстрактами крапивы и коры дуба» предпочтение отдано ясности первого. У FineReaderа «язык не повернулся» признать дуб травой на фоне нарисованных вишневых листьев.
О правдоискательных свойствах своей программы разработчики пока не догадываются, поскольку принятый ими новый логотип тоже не проходит этого теста (см. рис. 1). И вправду, какой смысл в отечественной разработке акцентировать внимание на однозначно немецком родовом определении «…der OCR» в концовке логотипа? Это не улучшает распознавания сцепленных строчек.
Следует ли говорить, что условия распространения FineReader’а в качестве детектора лжи никак не отражены в лицензионном соглашении. Поэтому вопрос о легитимности использования контрафактных версий в указанных целях остается дискуссионным. Однако в случае его положительного решения для себя лично будьте готовы к сюрпризам: противопиратские мины-ловушки срабатывают даже после успешной инсталляции (рис. 6). Правда, иногда «бьют и по своим» - в данном обзоре рассмотрена лицензионная коробочная версия. 1 (обратно к тексту) - Здесь и далее цитаты с официального сайта. 2 (обратно к тексту) - Около 95% «праворуких» людей справляются с чтением силами левого полушария мозга, 5% - правого. 70% «леворуких», как ни парадоксально, также используют левое полушарие, 15% - правое, и еще 15% - оба полушария. 3 (обратно к тексту) - Блум Ф., Лейзерсон А., Хофстедтер Л. - Мозг, разум и поведение. Пер. с англ. - М.: Мир, 1988. с. 182-183. 4 (обратно к тексту) - Вниманию разработчиков! «Первая компьютерная программа, видящая и толкующая сны» - вакантный слоган. 5 (обратно к тексту) - Конечно, это всего лишь попытка объяснить чисто случайное совпадение. |
|
| 2000-2008 г. Все авторские права соблюдены. |
 Радость
более совершенна, чем знание, ибо не каждый в процессе познания радуется, но
всякий, кто радуется - познает при этом.
Радость
более совершенна, чем знание, ибо не каждый в процессе познания радуется, но
всякий, кто радуется - познает при этом.