
|
|
Библиотека Интернет Индустрии I2R.ru |
||
FineReader 6.0: повторение успеха
Принцип работы с FineReader 6.0, появившимся на прилавках магазинов в середине весны этого года, прост и понятен даже тем пользователям, которые никогда ранее не сталкивались с OCR-продуктами. Благодаря наличию нескольких средств автоматизации пакет позволяет поставить распознавание поступающих документов на поток, тем самым резко снижая затраты драгоценного времени. С первого взгляда становится ясно, что интерфейс программы был изменен, но не отошел от той раскладки панелей и меню, к которой привыкло подавляющее большинство пользователей FineReader. По-прежнему слева столбиком выстраиваются уменьшенные копии страниц загруженного документа, центральную часть экрана занимают окна с оригинальным изображением и результатом, получившимся в процессе распознавания. Все детали оформления слегка модифицированы в соответствии с нынешней ХР-модой. На функциональность это, разумеется, никоим образом не влияет. Зато наполнение панелей кнопками теперь поддается пользовательской настройке, что весьма кстати (количество элементов управления увеличилось, и всем сразу уместиться на экране трудно). 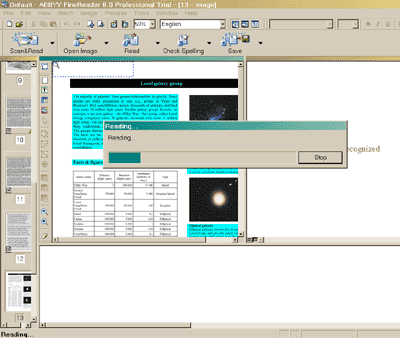 «Косметический ремонт» пользовательского интерфейса не затронул принципы построения рабочего окна программы Интересно также отметить повысившийся уровень интеграции FineReader 6.0 с другими офисными программами. Благодаря разнообразию выходных форматов файлов, в которые пользователь может экспортировать результаты своей работы, отсканированные и распознанные документы быстро обретают электронную форму и в требуемом виде включаются в документооборот. Хотя и предыдущие версии FineReader умели отправлять данные, например, в программы из семейства MS Office, новая версия делает это более качественно и избавляет человека от необходимости вручную править получившийся текст. Однако большая часть появившихся в FineReader 6.0 новинок не заметна рядовому пользователю. В основном они касаются самого механизма анализа загруженной информации, математических алгоритмов распознавания знаков препинания, коррекции лексических и грамматических ошибок, т. е. того, что принято называть ядром или движком. Пожалуй, наиболее полезное с практической точки зрения новшество заключается в появившихся способностях FineReader работать с файлами, записанными в формате PDF (Portable Document Format). Когда-то этот стандарт документов был не очень распространен, но год от года его популярность среди рядовых пользователей РС росла. По крайней мере, в Интернете наблюдается стабильная тенденция к публикации самых разнообразных материалов именно в этом формате. Причин тут несколько. Во-первых, PDF позволяет легко и незаметно преодолеть межплатформенные барьеры: файл будет выглядеть абсолютно одинаково вне зависимости от того, был ли он создан на Macintosh, в среде Windows или вообще на машинах Sun. Во-вторых, формат идеально подходит для хранения сложных документов, насыщенных графическими иллюстрациями, таблицами, диаграммами и т. п. К тому же гарантируется качественный вывод на печать вне зависимости от того, в какой программе файл был открыт. Таким образом, многочисленные достоинства PDF налицо. Между тем предыдущие версии FineReader не позволяли открывать PDF-файлы напрямую. В случае необходимости их приходилось распечатывать на принтере, сканировать и только затем передавать программе в виде растровых изображений. Масса времени уходила на совершенно лишние операции. Что же теперь? Отныне формат PDF поддерживается в FineReader на самом высоком уровне. Документ можно просто открыть и запустить на распознавание или же, наоборот, завершить работу с отсканированными страницами и экспортировать результат в PDF (при этом будут предложены различные варианты форматирования файла). Безусловно, эта функция нужна и удобна. Однако нельзя не отметить, что первый блин вышел комом. При попытке распознать попавшийся под руку PDF-документ FineReader 6.0 допустил досадную ошибку, приняв за текст фрагмент одной из иллюстраций. Причем неправильно опознанная зона находилась чуть ли не в самой середине картинки, где, следуя простой логике, тексту вообще нечего делать. Так что, несмотря на все усовершенствования алгоритмов, составляющих ядро программы, полагаться на автоматическое деление страниц на зоны по-прежнему нельзя, по крайней мере, в тех документах, где присутствуют графические и другие сложные объекты. Распознавание текста, не обремененного большим количеством иллюстраций, нареканий не вызвало. 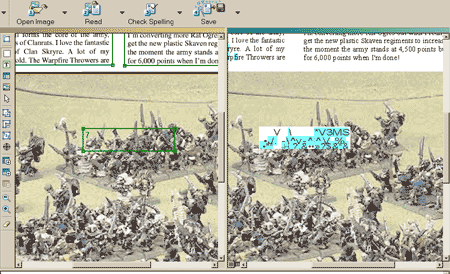 Чтобы детали иллюстраций не воспринимались программой как текст, придется немного поработать руками Что же касается этих самых пресловутых обновленных алгоритмов, то на них тоже удалось посмотреть в действии. Согласно словам разработчиков, одним из достоинств нового движка FineReader 6.0 стала его работа с оригиналами низкого качества, попадающимися сплошь и рядом. Изредка в этом виноват сам сканер, но намного чаще — источник, с которого проводится сканирование. Если сам документ напечатан на серой рыхлой бумаге или, скажем, ксерокопирован с факсимильного сообщения, то его бывает непросто прочитать даже человеку, вооруженному увеличительным стеклом. Что уж говорить о компьютерной программе! Именно поэтому в FineReader 6.0 был встроен механизм фильтрации фона как основного источника помех при распознавании, работу которого мы просто не могли не протестировать. Было решено изготовить максимально «нечитабельный» документ. С этой целью с открытого в текстовом процессоре фрагмента пришлось снять скриншот, развернуть его в графическом редакторе на один градус (далеко не всегда мы кладем страницы в сканер идеально ровно), понизить освещенность и контрастность, немного размыть контуры, добавить пиксельного «шума» и под конец экспортировать изображение в файл формата JPEG со средним уровнем компрессии. На вид результат получился слегка жутковатым: некоторые слова прочесть было абсолютно невозможно. FineReader 6.0 обрабатывал документ долго, заметно дольше, чем те, которые обладали нормальным качеством. В итоге текст был прочитан, но далеко не безупречно: лишь чуть больше половины слов не содержали ошибок, а кое-где целые строчки превратились в месиво из случайных символов. Проверка ошибок немного исправила ситуацию, но признать результат удовлетворительным все-таки было нельзя. Конечно, в реальной жизни вам вряд ли удастся отыскать настолько некачественный документ. Тем не менее этот небольшой эксперимент наглядно продемонстрировал границы возможностей даже самых продвинутых современных технологий…  Документ столь низкого качества, как показал опыт, загружать в FineReader не стоит Последняя версия FineReader поддерживает 177 языков, что свидетельствует об ориентации на международные и региональные рынки. Именно на них, думается, и придется большая часть продаж программы: в России до сих пор многие пользуются не только пятой, но даже четвертой версией пакета и совсем не торопятся производить апгрейд. С другой стороны, корпоративных клиентов явно заинтересует утилита ABBYY FormFiller для автоматического распознавания данных, внесенных в типовые формы. Она входит в комплект поставки FineReader Corporate Edition, включающую в себя помимо прочего еще и средства для распределенной обработки сканируемого материала в рамках локальной компьютерной сети.  При установке FineReader довольно тесно интегрируется с системой. Здесь вы видите кнопку быстрого запуска программы, которая была добавлена на стандартную панель инструментов MS Word Таким образом, все, чем FineReader 6.0 может заинтересовать среднестатистического покупателя (не считая, конечно, тех владельцев компьютеров, которые покупают OCR-программу впервые и не пользовались предыдущими версиями данного пакета),— это усовершенствованный интерфейс и повышение быстродействия. Согласитесь, довольно трудно изобрести что-то более удобное, чем кнопка Scan&Read, ставшая своего рода визитной карточкой FineReader.
Редакция благодарит компанию SoftLine за предоставленную программу. Юрий Анищенко |
|
| 2000-2008 г. Все авторские права соблюдены. |
 Программный пакет для распознавания текста
FineReader — один из лидеров на рынке OCR-продуктов — на протяжении нескольких
лет является незаменимым помощником в любом офисе, где активно используется
компьютерное оборудование. При этом сфера его применения не ограничивается только
русским и английским языками: новая версия 6.0 поддерживает уже более 150 других
языков.
Программный пакет для распознавания текста
FineReader — один из лидеров на рынке OCR-продуктов — на протяжении нескольких
лет является незаменимым помощником в любом офисе, где активно используется
компьютерное оборудование. При этом сфера его применения не ограничивается только
русским и английским языками: новая версия 6.0 поддерживает уже более 150 других
языков.