
|
|
Библиотека Интернет Индустрии I2R.ru |
||
Архитектура GoogleНынче стало модно сравнивать Google с «Матрицей» и «Скайнетом». Некоторых журналистов от таких мыслей берет озноб: «Google строит Суперкомпьютер будущего!» Они же недоумевают: «В настоящее время в распоряжении компании не менее 100000 компьютеров. Очень сложно представить не только то, сколько физически могут занимать эти сервера, но и каким образом персоналу удается их обслуживать». Действительно, когда задумываешься над тем, как работают поисковые системы, голова идет кругом. Обычный компьютер с Windows на борту трудится несколько минут, чтобы найти файл на своем 200Gb диске. Google ищет по всему интернету и отвечает на любой запрос за секунду. Как? Постараемся разобраться, попутно ответив и на вопросы, заданные нашими любознательными коллегами. Сколько серверов обеспечивают работу Google, знают только инсайдеры компании. Может быть, рубеж в 100 000 машин уже взят, может быть, нет. В любом случае, счет идет на десятки тысяч компьютеров и парк их постоянно эволюционирует. Прежде всего, разберемся, зачем такая прорва машин, почему нельзя было ограничится небольшим количеством новейших суперкомпьютеров? Наверняка, их было бы легче обслуживать, чем тысячи серверов. Однако создатели Гугла научились не доверять технике, потому что в числе первых приоритетов у них всегда были безопасность и стабильность — вещи, с компьютерами мало совместимые. Компьютеры отказывают, а суперкомпьютеры — тем более. Когда у вас ломается десять машин из десяти тысяч — не беда, в крайнем случае, вы можете выбросить их и поставить новые. Когда у вас ломается суперкомпьютер — это уже ощутимо; его так просто не заменишь, нужно чинить, а значит связываться с нестандартным железом. Альтернатива суперкомпьютерам — кластерная архитектура, при которой большое количество стандартных серверов используются для параллельного решения задач. Для глобальной поисковой машины такое решение подходит идеально. Участвующие в кластере компьютеры разделены на несколько функциональных типов, которые мы подробно рассмотрим далее. Физически же это самые простые сервера, зачастую дешевле и медленнее тех, на которых крутятся сайты средней руки. Обычным проектам незачем делать кластер, поэтому, когда их вычислительные потребности превышают возможности сервера, у администраторов часто нет альтернативы апгрейду, установке дополнительного процессора или RAID-массива. Гуглу же все равно (с технической точки зрения), купить ли один мощный компьютер или два помедленнее. Важна не максимальная производительность юнита, а соотношение цена/скорость. Поэтому в кластер ставится опробованное, чуть устаревшее и потому подешевевшее железо. Любых сложных технических решений администраторы Гугла избегают. Даже RAID и SCSI, обычные для серверов, оказываются неоправданно дорогими. Таким образом, конфигурация Google-сервера примерно равна конфигурации настольного компьютера среднего уровня за исключением HDD — диски выбирают самые большие из имеющихся. Компьютеры постоянно докупаются, поэтому в Google работают целые поколения машин различного «года рождения». Однако разница в возрасте в цифровом мире не может превышать 2–3 лет, иначе сервера не уживутся в рамках кластера из-за слишком большого расхождения в производительности. Все компьютеры Google собирает специально для себя. Они устанавливаются в стойки, каждая из которых вмещает от 40 до 80 серверов (по 40 юнитов с каждой стороны стойки). При такой плотности размещения вопросы питания и охлаждения становятся критичными. Обычному серверу требуется около 100W, при стандартном КПД блоков питания в 75% получается, что на вход нужно подавать 120–130W. Серверная стойка занимает около 2.3 m2, следовательно, на каждый квадратный метр требуется 4500W. При использовании более мощных машин плотность достигает 8000 W/m2. При этом стандартная плотность, которая предлагается коммерческими датацентрами — от 700 до 1800 W/m2. Поэтому не только сервера, стойки, но и сами датацентры Гуглу приходится подстраивать под себя. Стоимость альтернативных систем охлаждения и серверов с пониженным энергопотреблением слишком высока. Стойка 10kW потребляет около 10 MWh в месяц. При цене в 15 центов за kW/h (половина идет на собственно оплату энергии, другая на поддержку систем бесперебойного питания и распределения мощностей) получается, что одна стойка обходится в $1500/месяц. Использование нетрадиционных решений на хардверном уровне, по подсчетам специалистов компании, будет обходиться не менее чем в $5000/месяц за счет амортизации дорогостоящего оборудования. Географически кластеры находятся в разных частях планеты, что позволяет не бояться ни природных катаклизмов, ни массовых отключений электричества. Русские пользователи наверняка помнят, как Яндекс полностью отключился из-за аварии на подстанции. Поисковику, который обслуживает всю планету и при этом котируется на бирже, таких промахов позволять себе не стоит. На своих серверах Google использует модифицированное ядро Linux и все программное обеспечение пишет самостоятельно. Во-первых, разработки компании во многом не имеют аналогов. Во-вторых, используя собственные управляющие программы не нужно тратить деньги на покупку лицензии (ужас корпоративных сетей и, кстати, аргумент против распространения кластеров). Софт превращает кластер в единый организм, подчиняет сотни компьютеров выполнению одной задачи. 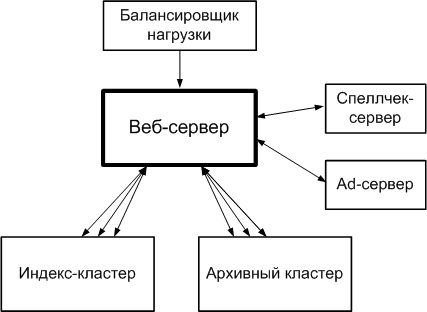 Когда пользователь вводит запрос в Google, браузер обращается к DNS-серверу, а тот отправляет его на один из кластеров, наиболее близкий и наименее загруженный. После этого все операции проходят внутри этого кластера. По схеме 1 можно отследить процессинг поискового запроса. Но прежде чем это сделать, вкратце разберемся, что собой представляет индекс, главное богатство поисковых машин. Но прежде чем это сделать, вкратце разберемся, что собой представляет индекс, главное богатство поисковых машин. Он не содержит информацию в явном виде: прежде чем «проиндексироваться», страница проходит через ряд преобразователей. Определяется, какие слова встречаются в документе, с какой частотностью, на каких позициях, с какой гарнитурой и так далее. Эти данные формируют так называемый хит-лист (hitlist) и сохраняются в оптимизированном для поиска формате на индексных серверах. Прямой индекс содержит идентификаторы документов (docID), каждому из которых соответствует список идентификаторов слов (wordID). При поиске же используется инвертированный индекс. В нем, наоборот, каждому wordID соответствует docID-список. Хит-листы используются в обоих индексах. Параллельно с индексом Гугл хранит кеш, полные текстовые копии страниц, каждой из которых соответствует docID из индекса. Они лежат на архивных серверах (document servers). Итак, пройдя через аппаратный распределитель нагрузки, запрос попадает на один из веб-серверов, который координирует действия всех других машин. Процесс обработка запроса делится два основных этапа. На первом слова, введенные пользователем, перекодируются в wordID и индексные сервера с помощью инвертированного индекса формируют список docID, отсортированный по релевантности. На втором этот список через веб-сервер передается архивным серверам. Они извлекают заголовки страницы и сниппеты — те куски текста, которые содержат наибольшее количество ключевых слов и кажется поисковику наиболее релевантным. Вся эта информация возвращается веб-серверу, и он формирует «выдачу» — ту HTML-страницу с результатами, которая предъявляется пользователю. Помимо основных этапов есть и другие, которые появились позже: отбор контекстной рекламы и проверка правописания запроса. Эти задачи решаются соответствующими серверами. Алгоритм спеллчека, кстати, является примером самообучения системы, потому что основан не на словарях, а на опыте обработки запросов. Главное препятствие, которое возникает при интернет-поиске, это огромные объемы информации. Несмотря на то, что в результате «индексирования» размер сайтов уменьшается в разы, все равно в сумме мы имеем многие терабайты информации на индексных серверах. А в архивном кластере по сути хранится весь интернет, несколько миллиардов страниц, причем каждая страница должна быть доступна в любое время и без всякой задержки… Мы, наконец, подходим к самому интересному, к собственно кластерной архитектуре Гугла, которую будем описывать шаг за шагом. Кластер состоит из одного мастер-сервера (master server) и многих дата-серверов (chunkservers), к нему постоянно обращаются клиенты, которые могут быть установлены на отдельных машинах, а могут помещаться на дата-серверах (см. схему 2). Все файлы разделены на блоки (chunks) фиксированной величины. Поскольку Гуглу приходится иметь дело с огромными массивами информации, используется беспрецедентно большой размер — 64Mb. Всем блокам присваиваются уникальные 64-битные идентификаторы (chunk handle), которые хранятся на мастер-сервере в качестве метаданных. В целях безопасности блок после записи копируется еще на два дата-сервера, таким образом, в любой момент времени всякий файл доступен в трех экземплярах. 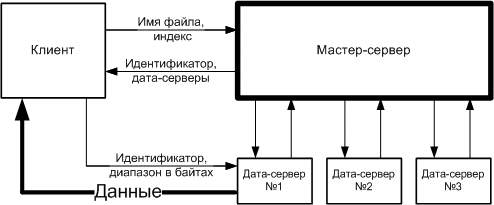 Мастер-сервер хранит в памяти всю метаинформацию. Он координирует взаимодействие кластера с клиентами, следит за тем, чтобы все данные были в норме. Поскольку мастер один, нельзя, загружать его большим объемом трафика, иначе в системе появится узкое место. Как можно видеть на схеме, поток данных никогда не проходит через мастер, вместо этого клиенты запрашивают у него адреса нужных дата-серверов и общаются непосредственно с ними. При этом адреса выдаются клиентам, хранятся у них в кеше определенное время, затем стираются — все вместе называется арендой дата-сервера. Весь процесс на примере простейшей операции чтения показан на схеме 2. Клиент, зная, что все файлы делятся на куски по 64Mb, преобразует нужный ему диапазон байт во индекс блока (chunk index) и отправляет его вместе с именем файла мастеру, а в ответ получает идентификатор и названия дата-серверов, на которых хранятся копии. После этого клиент отправляет ближайшему дата-серверу запрос, в котором содержится идентификатор блока и диапазон в байтах. Если клиенту потребуется вновь считать что-нибудь из того же блока, ему не нужно будет общаться с мастером до тех пор, пока не обнулится кеш. Очевидно, поэтому важно было увеличить размер базового блока в файловой системе: чем он больше, тем меньше клиенту нужно общаться с мастером, тем меньше нагрузка на сеть. Теперь рассмотрим, как происходит запись новой информации (схема 3), это позволит нам понять и механизм репликации. Как уже упоминалось, каждый блок в рамках кластера хранится одновременно на трех дата-серверах. На время записи мастер-сервер назначает одного из этой тройки главным (primary) и передает ему контроль за правильным выполнением операции. 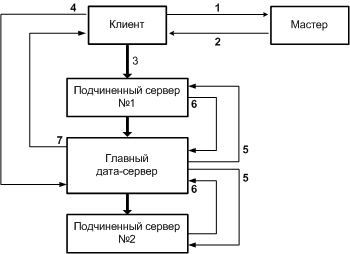
Ошибки на любом из шагов отслеживаются, действия с 3 по 7 могут повторяться несколько раз, прежде чем весь процесс будет запущен заново. Если, например, один из подчиненных серверов не смог полностью записать нужную информацию в блок, он будет повторять попытки. Допустим, одна из попыток окажется успешной после перезагрузки сервера (перезагрузка всегда совершается принудительно простым уничтожением процесса, поэтому занимает несколько секунд). В результате повторной записи файл блока окажется больше, чем два его собрата. Таким образом, Гугл не может гарантировать побайтную точность всех копий, но это и не требуется — главное, чтобы вся информация была успешно записана, а адреса переданы клиенту и мастер-серверу.
Теперь рассмотрим механизм, который позволяет мастеру быть в курсе всего происходящего. Каждый дата-сервер при запуске отсылает свою адресную информацию, мастер сохраняет ее и периодически обновляет с помощью так называемых Heartbeat запросов. Все данные хранятся в оперативной памяти, что обеспечивает нужную скорость коммуникаций. Если дата-сервер не отвечает на запрос, информация о нем стирается после очередной проверки. Весь его контент должен быть ре-реплицирован. Мастер посылает оставшимся в строю дата-серверам информацию о том, куда им нужно копировать часть своих блоков. При выборе нового места система руководствуется следующими соображениями: выбираются сервера, во-первых, с наименьшей дисковой загрузкой, во-вторых, с наименьшем количеством недавно созданных файлов, в-третьих, находящиеся в соседних стойках и, соответственно, подключенные к другим свичам. Другой случай ре-репликации — профилактический, в целях более точной балансировки нагрузки. Когда к кластеру подключают партию серверов, их нельзя наводнять новыми файлами, иначе образуется так называемый hot spot, место с неоправданно высокой нагрузкой. Поэтому мастер копирует часть уже заполненных блоков, освобождая диски старых серверов. Каждый блок в системе имеет свою версию (chunk version), которая обновляется после любого успешного изменения. Если дата-сервер некоторое время был недоступен и пропустил ряд операций, а потом вернулся в сеть, часть его информации оказывается просроченной. Если версия файла меньше текущей, он подлежит удалению. Удаление файлов осуществляется не мгновенно. Сначала файл исчезает из индекса мастера и переименовывается. Если через три дня он не возвращается в индекс, то во время очередной проверки мастер дает команду на удаление. Такой подход имеет несколько преимуществ. Поскольку «уборка мусора» проходит систематически, не возникнет проблем в случае потери единичного запроса на удаление. Кроме того, все действия совершаются во время регулярных сеансов связи мастера с дата-серверами (Heartbeat) и потому не требуют дополнительной нагрузки на сеть. Для Google отказ оборудования является нормой, а не исключением. Сервера и компоненты выходят из строя каждый день. Механизм репликации позволяет сохранить информацию в целостности: блок нельзя восстановить только в том невероятном случае, когда в течение нескольких минут кластер безвозвратно теряет три независимых сервера. В любом случае, опасности подвергается лишь малая доля информации. Гораздо более опасна потеря мастер-сервера, поэтому он защищен еще надежнее, чем дата-сервера. Все, что происходит в рамках кластера, записывается в лог, который имеет несколько копий, как и вся остальная информация системы. Никакие изменения не становятся публичными до тех пор, пока мастер не удостоверится в успешной репликации лога. В кластере существуют так называемые «тени» мастер-сервера. Они повторяют за мастером все операции, отслеживая изменения по логам. Их метаинформация может быть чуть устаревшей, на доли секунды, поэтому они предоставляют доступ в режиме read-only, только для чтения. При отказе мастер-сервера контролирующие службы запускают мастер-процесс на другой машине. Поскольку он фигурирует в сети под доменом (скажем, gfs-master), достаточно поменять DNS-алиас, прописав новый IP-адрес, чтобы вернуть кластеру работоспособность. Это единственный случай поломки оборудования, с которыми файловая система Google не может справиться автономно и требуется вмешательство извне. Текст - Александр Азаров |
|
| 2000-2008 г. Все авторские права соблюдены. |