
|
|
Библиотека Интернет Индустрии I2R.ru |
||
Интернет: ищущий да найдет
Я хотел спасти от забвения один из таких третьестепенных ужасов: беспредельную и разноречивую Библиотеку, где вертикальные пустыни сменяющихся книг бесконечно переходят друг в друга, возводя, руша и путая все на свете, как впавший в горячку Бог. О поиске информации в Интернете имеется невероятно много и становится все больше этой самой информации. Опять же, не только на бумаге, но в еще большей мере - в самом Интернете. И, понятное дело, найти что-нибудь нужное - довольно затруднительно. Причин тому несколько, но есть две главные: во-первых, в Сети нет изначально встроенного слоя семантики, нет даже униформального индексирования, а во-вторых, Сеть проявляет признаки эволюционирующего организма, на котором строить менее динамические, чем она сама, информационные структуры, мягко говоря, малополезно. Тем не менее, с определенным успехом искать нужную информацию в Интернете все-таки возможно. Просто о сложном, сложно о простомСейчас уже мало кто помнит о предтечах Интернета, например о проекте Xanadu, который стал делом жизни технократа-романтика Теодора Нельсона 1. А ведь в случае успешной реализации Xanadu мы жили бы в другом, более совершенном мире. У Нельсона могли оставаться справедливые претензии к Тиму Бернерсу-Ли 2, который хоть и увлекся идеями Теодора, но воплотил их в куда более грубой форме. Достаточно сказать, что в Xanadu гиперссылки были двунаправленные (чего не хотел воспринимать как потребную сущность наш <когдатошний> компьютерровский главный редактор Георгий Кузнецов), то есть всегда можно было бы пройти путь вспять, чего, в общем случае, не обеспечивает нынешняя конструкция Интернета. Задолго до того, как распространился милый сердцам народов протокол http, детище Бернерса-Ли, в Интернете существовали информационные хранилища 3, построенные на основе других соглашений, например изначального протокола telnet или же другого - gopher, которых было вполне достаточно для работы с научной информацией 4. Характерно, что авторы бесчисленных статей и рекомендаций, имеющих отношение к проблеме поиска информации в Интернете, впадают в одну из двух крайностей 5. Часть авторов скатывается к примитивной технологизации проблемы и всё сводит к использованию поисковых машин, благо их расплодилось что кроликов в австралийских степях. Именно на этих артефактах возникают новые классификации, формализуются методики и выдаются на-гора диссертации. Другая часть пытается привлечь давно существующие методы работы с научной и технической информацией в приложении к специфике Интернета. Опусы такого рода не только скучны, но и бесполезны - для дела там ничего не найти. Всякого рода индексы цитирования, совершенно неприменимые для данного предмета, статистические распределения и прочая схоластика - все это не более чем попытки выйти на удобное наукообразие. И тут вспоминаешь, что противоположности всегда в чем-то подобны. В общем-то, вряд ли следует пренебрежительно относиться к поисковым машинам - без них не обойтись. Не нужно гнушаться и азами теоретических премудростей - знать хотя бы определение индексирования 6 как метода поиска информации в хорошо структурированных массивах данных тоже полезно. Но важнее другое: поиск информации в Интернете - это совокупность методов, приемов и инструментов, применение которых в синергизме приводит к желаемому результату. Кроме того, и, может быть, самое главное, - это персональный опыт поиска и обработки информации, своего рода наработанная интуиция. Итак, с точки зрения человека традиционной печатной культуры, Интернет столь плохо поддается попыткам найти в нем нужные данные из-за отсутствия строгого индекса. По той же причине поисковые машины на любой запрос вываливают тысячи и сотни тысяч результатов, релевантных лишь в очень незначительной степени. Сложилось так, что в запросах между ключевыми словами поисковые машины по умолчанию проставляют знаки логического <И> или даже <ИЛИ> 7, то есть одновременного или раздельного присутствия заданных терминов в телах обнаруженных документов: предикат, выражаясь термином логики, оказывается очень обширным, он покрывает огромную часть пространства, на котором ведется поиск. Эта тактика особого успеха не приносит, поскольку у больших поисковых машин бывает под прицелом (то есть проиндексировано) полмиллиарда и больше отдельных документов в WWW (у Google - более трех миллиардов!). Вообще, по моему опыту, в результате простого поиска по незакавыченной фразе доля выявленных ссылок, имеющих хоть какое-то отношение к цели поиска, в среднем не превосходит 5%. А потому выработаны эмпирические правила (они бывают разными), позволяющие повысить эффективность изысканий в Интернете. Прежде всего, следует четко представлять, как готовить поиск. Нужно идентифицировать основной предмет, ядро темы, и попытаться составить для него список синонимов, антонимов, аналогов, параллелей, альтернатив, различий в написании и произношении. И второе: нужно знать особенности инструментов. Например, предметный каталог Yahoo во всем отличен от <чистых> поисковых машин типа Google или Altavista. Даже поисковые машины отличаются друг от друга, о чем немного ниже. Итак, перейдем к делу. Сравнительные характеристики главных поисковых машин.Актуальные данные по количеству индексированных документов доступны на машинах Google и Altavista, данные для других машин приведены по состоянию на 1 июля 2001 года (источник: Phil Bradley).
О пользе предметных каталоговПредметные каталоги (subject directory) представляют собой наборы ссылок на сайты, организованные по некоторым содержательным (но все равно субъективным) свойствам. Каталоги иногда называют поисковыми деревьями, поскольку они ветвятся по мере уточнения искомой концепции. Примером поиска в предметном каталоге может служить, скажем, такое уточнение: <автомобили - иномарки - Audi - модели - цены - условия приобретения>. Интересным свойством каталогов является то, что в них можно включать свои собственные темы. Таким образом, желая приступить к долговременным исследованиям предмета, полезно найти ему место в каком-либо популярном каталоге, например в Yahoo. Есть вероятность, что новая тема (а именно - ссылка на ваш сайт) станет ядром <кристаллизации> - уже без вашего участия. Каталоги полезны, когда предмет поиска расплывчат и точные термины для него подобрать трудно. Большинство развитых каталогов имеют внутренние поисковые механизмы, помогающие преодолевать много уровней уточнений. Недостаток каталогов заключается в их малой мощности: обычно они охватывают лишь небольшую часть Интернета, в частности страницы общего, учебного и научного содержания. Самый большой и известный каталог, конечно же, Yahoo. Собственно, в годы становления Интернета, когда классификации поисковых инструментов еще не существовало, Yahoo относили к поисковым машинам. Этот каталог заслуженно признается одним из лучших мест для поиска информации общего содержания. Если чего-то не удалось найти в Yahoo, можно поискать в Looksmart или Open Directory, тоже очень хороших каталогах. Опыт № 1. ПозитивныйЗайдя однажды на сайт аналитического агентства Jupiter Media Metrix, я был приятно поражен: мне удалось скачать файл в формате pdf, наполненный всякого рода чудесными историями об онлайновых услугах для цифровой фотографии. Этот огромный файл все еще ждет своего читателя, надеюсь вскоре обновить информацию и подать ее <свежачком>. Обращаю ваше внимание: мне удалось сделать это только потому, что я был зарегистрированным клиентом аналитической системы JMM, а потому мне было дозволено пользоваться встроенной поисковой машиной (см. скриншот). 
Поисковые машиныВ Интернете функционирует несколько сотен разных поисковых машин. Конечно, хорошо бы каждую из них проверить в деле, дабы выбрать те, которые наилучшим образом отвечают целям вашего поиска. Однако нельзя объять необъятное… Есть мнение 8, что существует пять типов поисковых машин. Они осуществляют:
Алгоритмы функционирования этих машин заметно отличаются, а потому дадим краткие разъяснения по каждому из типов. Опыт № 2. НегативныйСамые большие неудачи случаются при поиске информации о самых недавних событиях - ее просто изымают с сайтов. Кажется, что она навсегда канула в Лету. Поневоле вспомнишь Гегеля с его замечанием о науке истории… Кроме того, можно вспомнить о продолжающемся подвиге Брюстера Кале, основателе информационной системы WAIS, пытающемся остановить мгновенья и запечатлеть все информационные процессы человечества 12. С моей точки зрения, его потуги просто тщетны… увы. Вообще, жизнь показывает, что хранить информацию тем дороже, чем плотнее она размещена на носителе. В этом плане есть мера и норма божественной компактности нашего мироздания. Поиск по произвольному текстуМашине задается любое слово, термин, фраза, что заблагорассудится. После этого она начинает искать подобия заданного ключа на сайтах, фигурирующих в базе данных машины. По окончании поиска выдается список обнаруженных сайтов. Как правило, если не задать специальную конструкцию ключевой фразы, то по умолчанию машина ставит между отдельными словами (терминами) логическое «И» (еще более осложняет ситуацию постановка «ИЛИ»), что приводит к очень размытым результатам - в списках могут появляться многие тысячи ссылок. Дабы повысить эффективность, машины ранжируют результаты, например, по релевантности, то есть полноте совпадений, или же по актуальности, то есть дате образования документа. Конечно, в работе каждой из машин есть свои особенности, а потому лучше всего опробовать несколько из них. Машины этого типа удобны в том случае, когда можно довольно точно сформулировать запрос. Сделать это не всегда просто: следует думать о терминах и определениях предмета, которых должно быть как можно больше - для более целенаправленного поиска. И вместо формулировки «цифровой фотоаппарат» следовало бы написать «цифровой фотоаппарат Olympus продажа». Впрочем, это тоже не гарантирует эффекта, результаты поиска могут оказаться весьма неожиданными. Таким образом, если не вполне понятно, что же конкретно нужно найти, машины этого типа оказываются малополезными. Поиск с индексированиемМашины, работающие по этому принципу, начинают поиск с вершины некоторого ветвления, уточняя категории на каждом следующем уровне - вплоть до достижения нужной группы сайтов. В этом есть некое подобие структурам предметных каталогов, но у каталогов структуры почти статичны, а поисковые машины «ведут проходку» в динамике - по последнему сформированному дереву. Они могут оказаться полезными, когда нужно получить представление о широкой предметной области. Ограничение очевидно: приходится бегать в пределах весьма жесткой классификационной схемы, что может оказаться не просто утомительно, но и расточительно по времени. 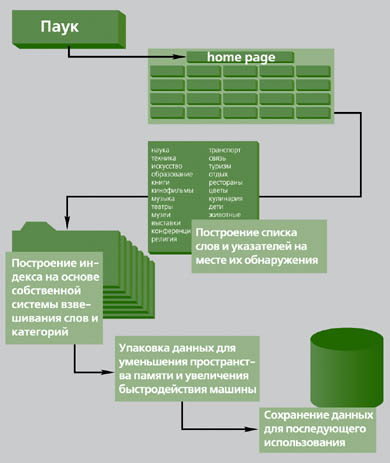
Множественный поискМашины этого типа вовсе не являются оригинальными поисковыми движками, это - метамашины. Они представляют собой входы (или, если хотите, порталы) к некоторым другим машинам, запросы к которым засылаются параллельно - через общий интерфейс. У этих устройств есть свои преимущества, например то, что они настраивают унифицированный пользовательский запрос на лексику и логику запроса каждой конкретной используемой машины 9. Естественноязыковый поискТут все понятно: как спросишь - так и получишь. Поиск специальныйСие определение тоже говорит само за себя - искать по предметам, доменам, группам участников и т.п. Хорошие новости GoogleДля тех, кто любит погурманничать свежими новостями, есть хорошая новость: с недавних пор на популярной поисковой машине Google появилась именно такая закладка - News. Этот проект пока пребывает в бета-фазе, а потому расположен на отдельном сайте news.google.com. Решение для этой службы поистине новаторское: идет сбор новостей более чем из 4 тысяч источников, после чего этот поток автоматически упорядочивается по разделам, в каждом из которых первыми представляются наиболее горячие новости. Процесс этот непрерывный, и, заходя каждый раз на сайт, можно обнаруживать изменение картины. Новый раздел Google замечателен еще и тем, что в нем унаследованны все свойства поисковой машины. В каждой из рубрик (например Science/ Technology) можно задавать ключевые слова, и на потоке будут выдаваться релевантные новости. Как они работают?Все поисковые машины имеют в своем составе то, что принято называть «робот» или «паук» 10 (см. рис. 1). Это программы, которые непрерывно обследуют пространство Интернета, переходя от ссылки к ссылке, - и так без конца. Если роботы находят новые сайты и страницы или обнаруживают, что содержание уже обследованных мест изменилось, они вытаскивают оттуда некоторую информацию и копируют ее в базу данных поисковой машины. Это именно та база, с которой имеют дело пользователи, задающие вопросы и запросы. ![[1]](/imgs/search/47060.jpg) Кстати, желающим сделать свой сайт популярным, вовсе не обязательно дожидаться, пока на него набредут роботы. Существует немало способов разместить ссылки на поисковых машинах немедленно 11. Поисковые машины в основном бесплатны. Деньги они зарабатывают тем, что либо предлагают собственные платные программные и аппаратные решения (например, Altavista продает программные корпоративные решения для поиска информации на разнородных базах данных), либо предоставляют место для внешней рекламы, которую почти неизбежно придется лицезреть при получении результатов поиска. Кое-кто пытался взимать деньги за поиск информации в Интернете, но это начинание не имело успеха, поскольку общепринятая практика - предоставлять подобные услуги бесплатно. Поисковые программыКроме машин, метамашин, разного рода поисковых порталов и прочих публичных онлайновых ресурсов, есть группа программных инструментов, устанавливаемых на локальные компьютеры. Они весьма удобны при необходимости точной настройки на круг запросов и интересов конкретной персоны. Этот класс программ называют по-разному, например, на Tucows их зовут «searchbots», чему на русском языке примерно соответствует «роботы-искатели» (месяц назад таких «искателей» числилось в обсуждаемом разделе примерно четыре десятка). Поскольку Tucows известная, но далеко не единственная система маркетинга и распространения программ (всяких - и бесплатных, и с публичными лицензиями, и шареварных, и коммерческих), то нужно говорить примерно о паре сотен существующих и доступных программ этого класса. В основу работы searchbots заложен следующий принцип: из запроса пользователя, сформулированного согласно несложным правилам самой программы-робота, вырабатываются запросы, специфические по синтаксису и логическим конструкциям для каждого отдельного целевого поискового ресурса в Интернете. То есть из одного получается множество настроенных запросов, которые рассылаются избранному кругу поисковых машин (и/или каталогов). Поисковые программы эволюционировали из метамашин, они обладают большей гибкостью и адаптивностью к потребностям персонального применения. Году в 1997-м я пользовался здравствующей и ныне программой WebFerret, логичной и удобной (скриншот 1). Но через два года на свет появилась программа Copernic (с августа этого года - Copernic Agent), и с тех пор я ей не изменяю (скриншот 2). Это очень мощное и понятное средство, позволяющее самостоятельно выбирать тематические категории, поисковый предметный домен, задавать состав глобальных поисковых машин, - всего и не описать. Результаты поиска хранятся в собственной базе программы, их можно сохранять в файлах стандартных форматов вместе с гипертекстовыми ссылками, размеры аннотаций можно менять, программа сама обновляет базы поисковых ресурсов при каждом подключении к Интернету. ![[2]](/imgs/search/47061.jpg) Но больше всего прельщает, что Copernic умеет вести индексацию там, где другие программы не работают, а именно на серверных поисковых машинах многих крупных издательств и агентств. К примеру, интересуясь текущим положением дел в корпорации IBM, нужно просто ввести эти три буквы (они и будут индексом) и выбрать категорию поиска «Top News». После этого Copernic сразу разошлет запросы по таким сайтам, как CNN, MSNBC, New York Times, Forbes… (впрочем, перечень грандов медиа тоже можно задать самостоятельно, см. скриншот 3). И будьте спокойны, объемом и качеством найденной информации вы обижены не будете. Конечно, как любое программное средство, Copernic требует в общении определенных навыков, но это приходит быстро. ![[3]](/imgs/search/47062.jpg) Я вовсе не собираюсь делать рекламу программе Copernic - она в ней не нуждается. Тем более что я не сомневаюсь в достоинствах многих других поисковых программ, цены на которые порой достигают сотни долларов. Просто каждый ищет то, что ему по душе и по карману. 2 (обратно к тексту) - И. Гордиенко. <Что же я породил?> (<КТ> #319 от 12.10.99, с.10). 3 (обратно к тексту) - И. Гордиенко. <Дело жизни Винтона Серфа> (<Инфобизнес> #5, 1996 г.). 4 (обратно к тексту) - И. Гордиенко. 5 (обратно к тексту) - И. Гордиенко. <Человек у истоков> (<КТ> #168 от 21.10.96). 6 (обратно к тексту) - Примером системы индексирования по содержательному признаку может быть применявшаяся в СССР система Универсальной десятичной классификации (УДК) для печатных изданий. В гротескной, но доходчивой форме объяснение индексированию дается в <Похождениях бравого солдата Швейка>, где вахмистр Фландерка сражался с анкетой за № 72345/721/a/f. 7 (обратно к тексту) - А что вы могли бы предложить в качестве более эффективной логики? Ведь у человека не столь уж много способностей для эксплицирования явного знания. 8(обратно к тексту) - Phil Bradley. Search Engines (www.philb.com). 9 (обратно к тексту) - И. Гордиенко. «Круизы по Сети на метамашинах - получите удовольствие!» («КТ» #173 от 25.11.96). 10 (обратно к тексту) - И. Гордиенко. «Слова, опять одни слова…» («КТ» #178 от 06.01.97). 11 (обратно к тексту) - И. Гордиенко. «Под тихий шелест листьев WWW…» («КТ» #175 от 09.12.96). 12 (обратно к тексту) - И. Гордиенко. «Хранить вечно» («Инфобизнес» #200 от 19.03.2002). Автор: Игорь Гордиенко |
|
| 2000-2008 г. Все авторские права соблюдены. |