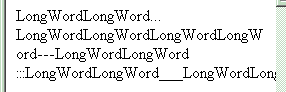|
|
Библиотека Интернет Индустрии I2R.ru |
||
Перенос и разбиение слов в HTMLПри создании различных лент новостей и колонок онлайн газет, web дизайнеры и программисты сталкиваются с ситуацией, когда в тексте попадается очень длинное слово (синхрофазотрон, http://www.enlight.ru/camera/117/index.html, и т.п.). Браузер при форматировании разбивает текст в тех местах, где есть пробелы (дефисы). Длинные слова при этом остаются нетронутыми, что часто приводит к "разъезжанию" ячеек таблицы, неаккуратному внешнему виду. Каким образом можно решить эту проблему?
Первое, что обычно приходит в голову - заранее отформатировать текст с учетом предполагаемой ширины колонки (например - php/perl/python скриптом) и выдать его браузеру уже построчно (с Очевидно, необходим более гибкий и аккуратный метод. Посмотрим, что нам предлагают авторы браузеров и стандартов. Microsoft предлагает хороший способ:
Или, если надо разрешить разрывы слов только на конкретном участке:
(знаки препинания вставлены произвольно)
В этом параграфе слово будет разбито автоматически. Одно плохо - метод работает только в MSIE 5.5 и выше (проверено в 5.5 и 6.0). Будем смотреть дальше: В стандарте на HTML 4 существует символ "­" - так называемый "мягкий перенос". Вообще же, это стандартный символ в Unicode и Latin-1 который Windows знает, но не всегда любит [правильно] показывать. Если его вставить в слово, например так: LongWordLongWord­LongWordLongWord ..то браузер в нормальных условиях этот символ не отобразит вообще. Однако, если места для слова не хватает, в этом месте оно должно быть автоматически перенесено на следующую строчку и появится знак переноса "-". Я говорю должно быть, поскольку браузеры - не всегда отражение стандарта на HTML.
Под MSIE 5.0.x все с виду работает, но в определенные моменты (при изменении размера окна браузера) определенные слова вдруг оказываются разбиты черточками без всякой на то видимой причины.
Помимо прочего, если поместить разбитую таким образом строчку в clipboard, а затем извлечь обратно - невидимые переносы превратятся в банальные "-". Это произойдет например в ICQ2000, GoldED 3.0.1/Win32, EditPlus. А Outlook и WinWord с одной стороны воспринимают "­" правильно, но с другой ведут себя с такими строчками немного странно. Очевидно, этот метод далек от совершенства - надо думать дальше. Если копнуть глубже, в черновом варианте стандарта HTML 3.2
упоминались применительно к Netscape любопытные тэги: <nobr> и <wbr>.
В MSIE 5.0.x и NS 4.05 необходимо писать так:
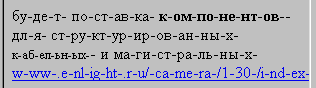
А вот в NS 6.x только так: LongWordLongWord причем если добавить Выводы из этой грустной истории такие: LongWordLongWord­ Другой вариант (возможно - лучший) - определять тип браузера и взависимости от этого генерировать текст с разбивкой нужными тэгами. Я написал для этого небольшую PHP функцию, возможно кому-то она будет полезна, после усовершенствования: # ----------------------------------------------------------------------------- # Если в строке $s встречается слово (последовательность символов без пробелов) # длиннее чем $wordmaxlen , оно ограничивается тэгами $leftlimit, $rightlimit и # разбивается тэгами $hyp на несколько слов, каждое из которых не # длиннее $wordmaxlen. Тэги бывшие в $s изначально - не затрагиваются. # # Примеры: # ($s,2,' Из остальных браузеров которые были под рукой: Opera 4.02, 5.12 вообще игнорирует все перечисленные способы. Lynx 2.8.4pre.5 напротив - поддерживает все, кроме варианта с "word-wrap:break-word;". Хотя идеального решения проблемы не найдено, но, надеюсь, кому-то я сберег время и нервы. Или наоборот - расшатал :) Что можно сказать в итоге? Все мы не питаем особой любви к Microsoft и другим крупным корпорациям-монополиям. Может, плоха не монополия, а то, что она существует для своих владельцев, а не для заинтересованного в стандартах и прогрессе общества? |
|
| 2000-2008 г. Все авторские права соблюдены. |